ZooKeeper笔记
logged in 2019 and written with Claude in 2026.
本文是学习 ZooKeeper 过程中的整理笔记,涵盖核心概念、Watcher 机制、ZAB 选举协议以及实践案例,主要参考官方文档与《从Paxos到ZooKeeper》。
What is ZooKeeper?
ZooKeeper is a centralized service for maintaining configuration information, naming, providing distributed synchronization, and providing group services.
ZooKeeper 是一个面向分布式应用的协调服务,核心能力包括:
- 配置管理:集中存储和分发配置信息
- 命名服务:为分布式资源提供统一命名
- 分布式同步:实现分布式锁、屏障等同步原语
- 集群管理:监控节点存活状态、Master 选举等
内部数据结构:ZNode
ZooKeeper 使用类 Linux 目录树结构组织数据,每个节点称为 ZNode,具有唯一路径名,并可存储少量数据。ZNode 支持变更通知(Watcher),使客户端能够感知数据变化。
在一致性方面,ZooKeeper 通过 ZAB 协议在集群内部保证强一致性与分区容忍性。
ZooKeeper 能做什么?
常见应用场景包括:分布式锁、服务注册与发现、配置中心、Leader 选举、分布式队列等。
Watcher 机制
参考:IBM Developer - ZooKeeper Watcher 详解
Watcher 的核心特性
| 特性 | 说明 |
|---|---|
| 一次性触发 | Watcher 触发一次后自动失效,需重新注册才能继续监听 |
| 串行回调 | 客户端回调在单线程中顺序执行,避免并发问题,但回调逻辑不能阻塞 |
| 轻量级 | 服务端只存储 Watcher 的存在标记,WatchEvent 不携带变更后的数据,客户端需自行重新读取 |
Watcher 基本流程
- 客户端通过
addWatch方法向服务端注册一个 Watcher - 服务端检测到对应事件发生后,封装一个
WatchEvent发送给客户端 - 客户端通过
WatchManager中缓存的回调函数进行处理
WatchEvent 可按 KeeperState(连接状态)和 EventType(事件类型)两个维度分类。
ZooKeeper 原理
分布式系统的核心挑战
在理解 ZooKeeper 的设计之前,需要先了解分布式系统面临的基本问题。
CAP 定理
分布式系统无法同时满足以下三点,最多只能保证其中两项:
| 属性 | 含义 |
|---|---|
| C(Consistency)一致性 | 所有节点在同一时刻看到相同的数据 |
| A(Availability)可用性 | 每个请求都能收到响应(不保证是最新数据) |
| P(Partition Tolerance)分区容忍性 | 网络分区发生时系统仍能继续运行 |
网络分区在分布式环境中是不可避免的,因此实际系统通常在 CP 或 AP 之间做取舍。ZooKeeper 选择了 CP:牺牲部分可用性(Leader 选举期间不提供服务),换取强一致性保证。
拜占庭将军问题与故障模型
分布式系统中的节点故障分两类:
- Crash Fault(崩溃故障):节点宕机、停止响应,不会发送错误信息。ZooKeeper 假设只存在此类故障。
- Byzantine Fault(拜占庭故障):节点可能发送任意错误或恶意消息。容忍此类故障需要 N ≥ 3F+1 个节点(N 为总节点数,F 为故障节点数)。
ZooKeeper 不处理拜占庭故障,仅需 N ≥ 2F+1(即超过半数存活即可),这也是为什么 ZK 集群通常部署奇数个节点(3、5、7)。
FLP 不可能定理
在异步网络环境中,即使只有一个节点可能崩溃,也不存在一个能在有限时间内保证达成共识的确定性算法。ZAB、Paxos、Raft 等协议的解决思路是:在实践中引入超时机制,将异步网络假设放宽为部分同步模型,从而绕过这一理论限制。
共识算法简述
ZAB 并非凭空设计,其背后是一系列共识算法的演进:
Paxos
Paxos 是分布式共识的理论基础,分为 Prepare 和 Accept 两个阶段,通过多数派投票达成一致。但原始 Paxos 描述的是单值共识,工程实现复杂,不直接支持日志复制场景。
Multi-Paxos → Raft
为解决 Paxos 的工程复杂性,Raft 将共识过程拆分为 Leader 选举、日志复制、安全性 三个相对独立的子问题,可读性更强,是目前最广泛实现的共识算法(etcd、TiKV 均基于 Raft)。
ZAB vs Raft
ZAB 与 Raft 思路相近,核心差异在于:
| 对比项 | ZAB | Raft |
|---|---|---|
| 设计目标 | 为 ZooKeeper 定制 | 通用共识算法 |
| 日志提交条件 | 超过半数 ACK | 超过半数 ACK |
| Leader 选举依据 | epoch + zxid | term + log index |
| 成员变更 | 不支持动态成员变更 | 支持(Joint Consensus) |
ZAB 协议详解
ZAB(ZooKeeper Atomic Broadcast,原子广播协议)是 ZooKeeper 的核心,保证所有事务在集群中以相同顺序被所有节点处理。
ZAB 的两个核心阶段
① 崩溃恢复(Leader Election + Recovery)
当集群启动或 Leader 宕机时进入此阶段:
- 所有节点进入 LOOKING 状态,开始投票
- 每个节点广播自己的投票:
(myid, zxid, epoch) - 收到投票后按以下规则 PK,更新自己的投票:
- 优先选
epoch更大的节点 epoch相同则选zxid更大的节点(数据更新)zxid也相同则选myid更大的节点
- 优先选
- 超过半数节点投给同一候选人,该节点成为新 Leader
- 新 Leader 与 Follower 同步数据,确保所有已提交事务不丢失
② 消息广播(Atomic Broadcast)
正常运行阶段,所有写请求统一由 Leader 处理:
Client → (任意节点) → Leader
↓ Propose(带 zxid)
Follower × N
↓ ACK(超过半数)
Leader Commit
↓ 广播 Commit
Follower Commit → Client 响应
这个流程类似两阶段提交(2PC),但 Leader 不等待所有节点确认,只需多数派即可提交,从而在容错性和性能之间取得平衡。
zxid 的结构
zxid 是一个 64 位整数,高 32 位为 epoch(每次 Leader 切换递增),低 32 位为事务序号。这个设计保证了跨 Leader 周期的全局事务顺序。
ZooKeeper 的一致性保证
ZooKeeper 提供的并非严格的线性一致性(Linearizability),而是顺序一致性(Sequential Consistency):
- 写操作:由 Leader 统一处理,全局有序,保证强一致
- 读操作:可能从 Follower 读到旧数据(Follower 同步存在延迟)
- 如需读到最新数据,需在读之前调用
sync()强制同步
参考:
实践案例:搭建 ZooKeeper 集群
参考:Docker 搭建 ZK 集群 - SegmentFault
① 搭建 ZK 集群(Docker)
方式一:逐个创建容器
拉取 ZooKeeper 镜像后,依次创建多个 ZK 容器,手动配置组成集群。
方式二:使用 Docker Compose(推荐)
编写 docker-compose.yml 配置集群拓扑,一键启动:
# 启动集群
COMPOSE_PROJECT_NAME=zk_test docker-compose up -d
# 查看运行状态
COMPOSE_PROJECT_NAME=zk_test docker-compose ps

② 连接集群验证
通过 Docker 连接 ZK 集群:
docker run -it --rm \
--link zk1 --link zk2 --link zk3 \
--net zk_test_default \
zookeeper zkCli.sh -server zk1:2181
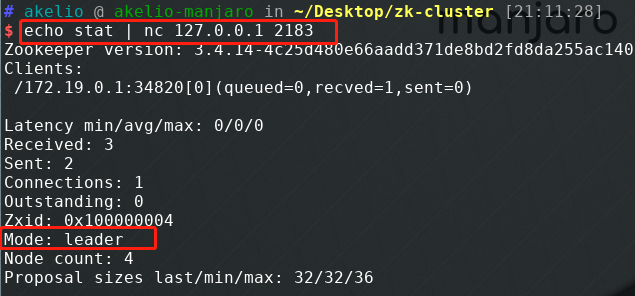
本地使用 nc 快速检查节点状态:
echo stat | nc 127.0.0.1 2181
echo stat | nc 127.0.0.1 2182
echo stat | nc 127.0.0.1 2183
实测结果:zk3(端口 2183)为 Leader,其余节点均为 Follower。
③ Java 客户端接入
常用客户端库:
- Apache ZooKeeper 原生客户端:官方提供,功能完整
- 101tec ZkClient:对原生客户端的封装,API 更友好
主要练习内容:
- 节点的增删改查
- 多线程竞争 Master(分布式锁场景)
- Watcher 的注册与回调
- 模拟服务器节点失效时的处理逻辑
参考资料
- ZooKeeper 入门 - 简书
- ZooKeeper 原理与实践 - 博客园
- 《从Paxos到ZooKeeper》
- 拜占庭容错为什么需要 N ≥ 3F+1 - 知乎
最后修改于 2019-05-01